DINOv3
This article provides a detailed guide on deploying Meta’s DINOv3 foundation vision model (released in 2025) on the NVIDIA Jetson Orin platform. It covers model introduction, system requirements, heatmap visualization, and two core application cases including unsupervised video stream segmentation, helping developers get started quickly and understand DINOv3’s visual representation capabilities.
1. Overview
DINOv3 is a Vision Transformer (ViT) model based on self-supervised learning and Gram anchoring technology. Compared to previous models such as DINOv2 and MoCo, it offers significant improvements in feature extraction generalization, dense feature quality, and spatial structure understanding. Key parameters and advantages include:
- Parameter Size: Available in multiple configurations such as 7B (7 billion parameters) to suit different computational resources.
- Training Data: Trained on an ultra-large-scale dataset of 1.7 billion images (e.g., LVD-1689M), covering a wide variety of scenes.
- Core Technology: Gram anchoring mechanism enhances inter-feature relationship modeling, addressing the weak local feature issue in traditional ViTs.
- Functional Features: Supports multi-task (classification, segmentation, detection), multi-resolution (flexible input sizes), and dense feature extraction (per-patch feature output).
- Performance Advantages: Outperforms on classification and segmentation tasks across benchmarks such as ImageNet and COCO.
| Method | Advantages | Limitations |
|---|---|---|
| MoCo/SimCLR | Simple and efficient, good for instance discrimination | Weak local features |
| iBOT/BEiT/MAE | Strong at inpainting & dense features | Lacks global consistency |
| DINOv2 | Self-distillation + contrastive learning, strong performance | Dense feature degradation in large models (e.g., ViT-L) |
| DINOv3 | Gram anchoring, large scale, strong dense features | Very high training resource requirements |
2. Environment Preparation
Hardware Requirements
| Component | Requirement |
|---|---|
| Device | Jetson Orin (Nano / NX / AGX) |
| Memory | ≥ 8GB (larger models require more) |
| Storage | ≥ 64GB (depends on model size) |
| GPU | NVIDIA GPU with CUDA support |
Software Requirements
- Ubuntu 20.04 / 22.04 (JetPack 5.1.1+ recommended)
- NVIDIA CUDA toolkit and drivers (included in JetPack)
- Docker (optional, for containerized deployment)
⚙️ 使用
jetson_clocks和检查nvpmodel,启用最大性能模式以获得最佳推理效果。
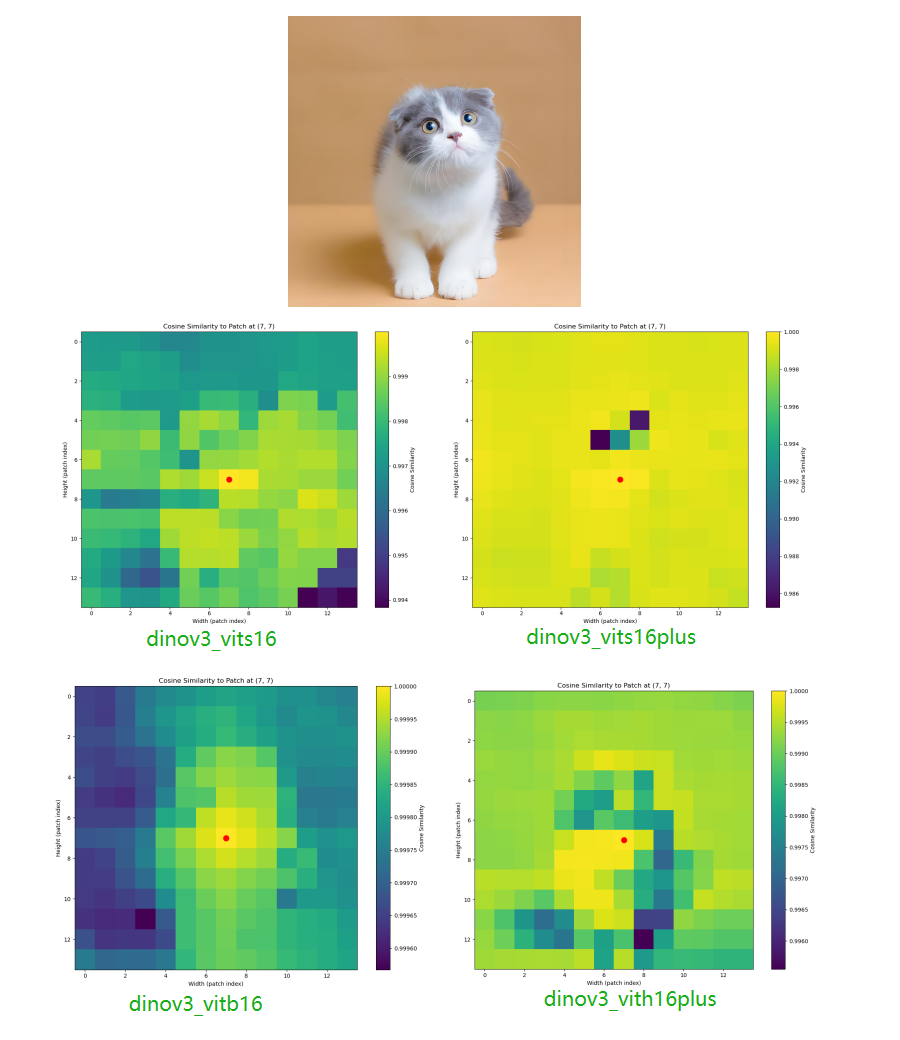
3. DINOv3 Patch Feature Heatmap Visualization Example
This example extracts patch features from an image using DINOv3, computes the cosine similarity between a target patch and all other patches, and generates a heatmap to visualize the model’s understanding of spatial structure (e.g., object part associations, contours).
3.1 System Environment Setup
Install JetPack SDK and core Python dependencies to ensure compatibility:
sudo apt update
sudo apt install python3-pip git -y
pip3 install --upgrade pip
pip3 install pillow transformers accelerate modelscope opencv-python tqdm addict simplejson sortedcontainers
pip install numpy==1.24.4
pip install "pyarrow==12.0.1"
pip install "modelscope[datasets]"
3.2 Obtain DINOv3 Source Code
Clone the official Facebook Research repository to get the model framework code:
git clone https://github.com/facebookresearch/dinov3.git
cd dinov3
3.3 Create Heatmap Visualization Test Code
Create a test_dinov3 directory and a dinov3_vision_test.py file as follows:
# Create working directory
mkdir test_dinov3
cd test_dinov3
# Edit test code
vim dinov3_vision_test.py
Sample code:
Note: To switch between different DINOv3 models (ViT Small/Base/Large, ConvNeXT), refer to the table below to modify the import and instantiation code. Ensure the weight file matches the model type, otherwise errors will occur. (For more model definitions, see
dinov3/models/vision_transformer.py)
| Model Type | Import Statement | Instantiation Example |
|---|---|---|
| ViT Small | from dinov3.models.vision_transformer import vit_small | model = vit_small(patch_size=16) |
| ViT Base | from dinov3.models.vision_transformer import vit_base | model = vit_base(patch_size=16) |
| ViT Huge | from dinov3.models.vision_transformer import vit_huge2 | model = vit_huge2(patch_size=16) |
import torch
import torchvision.transforms as transforms
import torch.nn.functional as F
import matplotlib.pyplot as plt
from PIL import Image
import argparse
import os
from dinov3.models.vision_transformer import vit_base
def compute_patch_similarity_heatmap(patch_features, H, W, target_patch_coord):
target_idx = target_patch_coord[0] * W + target_patch_coord[1]
target_feature = patch_features[0, target_idx]
similarities = F.cosine_similarity(
target_feature.unsqueeze(0),
patch_features[0],
dim=1
)
heatmap = similarities.reshape(H, W).cpu().numpy()
return heatmap
def plot_similarity_heatmap(heatmap, target_patch_coord, save_path=None):
H, W = heatmap.shape
fig, ax = plt.subplots(figsize=(10, 8))
im = ax.imshow(heatmap, cmap='viridis', aspect='equal')
ax.plot(target_patch_coord[1], target_patch_coord[0], 'ro', markersize=10)
plt.colorbar(im, ax=ax, label='Cosine Similarity')
ax.set_xlabel('Width (patch index)')
ax.set_ylabel('Height (patch index)')
ax.set_title(f'Cosine Similarity to Patch at {target_patch_coord}')
plt.tight_layout()
if save_path:
plt.savefig(save_path)
print(f"Heatmap saved to {save_path}")
else:
plt.show()
plt.close(fig)
return fig, ax
def main(image_path, model_path, patch_size=16, input_size=224, output_path="patch_similarity_heatmap.png"):
image = Image.open(image_path).convert("RGB")
transform = transforms.Compose([
transforms.Resize((input_size, input_size)),
transforms.ToTensor(),
])
tensor_image = transform(image).unsqueeze(0) # (1, 3, H, W)
model = vit_base(patch_size=patch_size)
state_dict = torch.load(model_path, map_location="cpu")
model.load_state_dict(state_dict, strict=False)
model.eval()
if torch.cuda.is_available():
model.cuda()
tensor_image = tensor_image.cuda()
with torch.no_grad():
features_dict = model.forward_features(tensor_image)
patch_features = features_dict["x_norm_patchtokens"]
num_patches = patch_features.shape[1]
H = W = int(num_patches ** 0.5)
target_patch_coord = (H // 2, W // 2)
heatmap = compute_patch_similarity_heatmap(patch_features, H, W, target_patch_coord)
plot_similarity_heatmap(heatmap, target_patch_coord, save_path=output_path)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--image', type=str, required=True, help='Path to input image')
parser.add_argument('--model', type=str, required=True, help='Path to DINOv3 .pth model')
parser.add_argument('--patch_size', type=int, default=16, help='Patch size (default=16)')
parser.add_argument('--input_size', type=int, default=224, help='Input image size (default=224)')
parser.add_argument('--output', type=str, default='patch_similarity_heatmap.png', help='Output heatmap image path')
args = parser.parse_args()
main(args.image, args.model, args.patch_size, args.input_size, args.output)
3.4 Download Pretrained Models
DINOv3 offers various architectures (ViT Small/Base/Large, ConvNeXT) and training sets (LVD-1689M, SAT-493M). Pretrained weights can be found on Hugging Face. Common models include:
3.5 Testing
Run the following command to generate a heatmap for a specified image (using ViT Base as an example):
python dinov_vision_test.py --image test.png --model dinov3_vits16_pretrain_lvd1689m.pth --output patch_similarity_heatmap.png
--image: Path to the input image.--model: Selected DINOv3 model.--output: Output path for the heatmap image.
Example output:
The generated patch_similarity_heatmap.png visually reflects the similarity between the selected patch and others, showcasing DINOv3’s understanding of spatial structure.
4. DINOv3 + KMeans Unsupervised Video Stream Segmentation Example
This example combines DINOv3’s patch feature extraction with KMeans clustering to achieve real-time, unsupervised video segmentation on Jetson Orin NX + imx219 camera, enabling foreground/background separation in video frames without manual labeling.
4.1 Principle Overview
-
DINOv3: A self-supervised Vision Transformer (ViT) model capable of learning rich visual structure features.
-
KMeans Clustering: Performs unsupervised clustering of patch token features for each frame, assigning each patch to a cluster for region segmentation.
-
Workflow:
- IMX219 camera captures video frames
- DINOv3 extracts patch features
- KMeans clusters the features
- Clustering results are visualized and overlaid on the original image
4.2 Environment Preparation
System dependencies:
Install required libraries for Scikit-learn clustering and PyTorch inference:
pip install scikit-learn Pillow
Hardware setup:
Connect the IMX219 camera to the device (ensure the metal contacts on the cable face up).

4.3 Obtain DINOv3 Source Code
Same as section 3.2, clone the dinov3 repository and enter the project directory.
4.4 Create Video Stream Unsupervised Segmentation Test Code
Create a test_dinov3 directory and a dinov3_kmeans_test.py file, and write the following code:
# Create working directory
mkdir test_dinov3
cd test_dinov3
# Edit test code
vim dinov3_kmeans_test.py
Sample code:
Note: To switch between different DINOv3 models (ViT Small/Base/Large, ConvNeXT), refer to the table below to modify the import and instantiation code. Ensure the weight file matches the model type, otherwise errors will occur. (For more model definitions, see
dinov3/models/vision_transformer.py)
| Model Type | Import Statement | Instantiation Example |
|---|---|---|
| ViT Small | from dinov3.models.vision_transformer import vit_small | model = vit_small(patch_size=16) |
| ViT Base | from dinov3.models.vision_transformer import vit_base | model = vit_base(patch_size=16) |
| ViT Huge | from dinov3.models.vision_transformer import vit_huge2 | model = vit_huge2(patch_size=16) |
import cv2
import torch
import torchvision.transforms as transforms
import numpy as np
from sklearn.cluster import KMeans
import time
from dinov3.models.vision_transformer import vit_base
def preprocess_frame(frame, input_size):
# OpenCV BGR to RGB
frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
pil_img = transforms.ToPILImage()(frame_rgb)
transform = transforms.Compose([
transforms.Resize((input_size, input_size)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
tensor_img = transform(pil_img).unsqueeze(0)
return tensor_img
def segment_with_kmeans(patch_features, H, W, n_clusters=3):
# patch_features: [1, num_patches, dim]
features = patch_features[0].cpu().numpy() # [num_patches, dim]
kmeans = KMeans(n_clusters=n_clusters, n_init=1, max_iter=50, random_state=0)
labels = kmeans.fit_predict(features)
mask = labels.reshape(H, W)
return mask
def mask_to_color(mask, n_clusters):
mask_norm = np.uint8(255 * mask / (n_clusters - 1))
mask_color = cv2.applyColorMap(mask_norm, cv2.COLORMAP_JET)
return mask_color
def main(model_path, patch_size=16, input_size=224, n_clusters=3):
model = vit_base(patch_size=patch_size)
state_dict = torch.load(model_path, map_location="cpu")
model.load_state_dict(state_dict, strict=False)
model.eval()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
gst_pipeline = (
"nvarguscamerasrc ! "
"video/x-raw(memory:NVMM), width=(int)1280, height=(int)720, format=(string)NV12, framerate=(fraction)30/1 ! "
"nvvidconv ! "
"video/x-raw, format=(string)BGRx ! "
"videoconvert ! "
"video/x-raw, format=(string)BGR ! "
"appsink"
)
cap = cv2.VideoCapture(gst_pipeline, cv2.CAP_GSTREAMER)
if not cap.isOpened():
print("Error: Camera not opened")
return
print("Camera opened successfully! Press 'q' to quit.")
while True:
t0 = time.time()
ret, frame = cap.read()
if not ret:
print("Can't receive frame. Exiting ...")
break
tensor_frame = preprocess_frame(frame, input_size)
tensor_frame = tensor_frame.to(device)
with torch.no_grad():
features_dict = model.forward_features(tensor_frame)
patch_features = features_dict["x_norm_patchtokens"] # [1, num_patches, dim]
num_patches = patch_features.shape[1]
H = W = int(num_patches ** 0.5)
mask = segment_with_kmeans(patch_features, H, W, n_clusters=n_clusters)
mask_color = mask_to_color(mask, n_clusters)
mask_resized = cv2.resize(mask_color, (frame.shape[1], frame.shape[0]), interpolation=cv2.INTER_NEAREST)
overlay = cv2.addWeighted(frame, 0.6, mask_resized, 0.4, 0)
fps = 1.0 / (time.time() - t0)
cv2.putText(overlay, f"FPS: {fps:.2f}", (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
cv2.imshow('DINOv3 + KMeans Unsupervised Segmentation', overlay)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--model', type=str, required=True, help='Path to DINOv3 .pth model')
parser.add_argument('--patch_size', type=int, default=16, help='Patch size (default=16)')
parser.add_argument('--input_size', type=int, default=224, help='Input image size (default=224)')
parser.add_argument('--n_clusters', type=int, default=3, help='Number of clusters for KMeans')
args = parser.parse_args()
main(args.model, args.patch_size, args.input_size, args.n_clusters)
4.5 Download Pretrained Models
For the KMeans segmentation example, use the pretrained weights for ViT Base/Large models (same as the heatmap example). Download links are in section 3.4.
4.6 Testing
Run the following command to start real-time video segmentation (example: ViT Base model, 2 clusters):
python test-dinov3-kmeans.py \
--model dinov3_vitb16_pretrain.pth \
--patch_size 16 \
--input_size 224 \
--n_clusters 2
-
--model: Path to the DINOv3 weight file, must match the model architecture (e.g., use vitb16 weights for vit_base). -
--patch_size: Patch size, usually 16. -
--input_size: Input image resize size, usually 224. -
--n_clusters: Number of KMeans clusters; 2 for foreground/background, 3+ for more regions.
Example result:
The system can perform unsupervised recognition of objects in the video, segmenting real-time video into foreground and background (or more regions) without manual labeling.

5. References
● Hugging Face DINOv3 Model Hub